
L’impact de l’IA sur la découvrabilité dans le secteur culturel – Février 2025
L’IA décentralisée: une perspective prometteuse pour les industries culturelles ?
Par Guy-Philippe Wells, Directeur scientifique, LATICCE
Pour vous inscrire à la liste de diffusion de la veille technologique sur l’impact de l’IA sur la découvrabilité dans le secteur culturel, ou pour nous faire parvenir vos commentaires et suggestions pour les prochaines éditions, bien vouloir remplir ce court formulaire.
Résumé
L’arrivée de Deepseek, un modèle d’IA chinois performant et peu coûteux, bouleverse le marché dominé par les géants américains comme Microsoft, Google, Meta et Anthropic. Son impact économique est considérable, entraînant une dévaluation massive des entreprises américaines du secteur. Sur le plan politique, plusieurs États, dont l’Australie et les États-Unis, interdisent son usage par crainte de risques liés à la cybersécurité et à la gestion des données personnelles. Deepseek pourrait transformer les industries culturelles en permettant une création artistique plus accessible et indépendante des grandes plateformes. Son modèle frugal et ouvert offre une alternative aux infrastructures coûteuses des multinationales de l’IA, suggérant une possible décentralisation du marché. Cette veille propose ainsi un système utilisant ces développements de l’IA où les œuvres musicales seraient gérées directement par les sociétés de gestion collective, réduisant les coûts et garantissant une meilleure rémunération des artistes. Cette vision s’oppose au modèle des plateformes comme Spotify, critiqué pour son manque de transparence et la faible redistribution des revenus. Par ailleurs, l’Union européenne tente de jouer un rôle de régulateur, notamment en matière de protection des données et des droits d’auteur, mais les tensions persistent entre innovation et encadrement juridique. L’enjeu est de trouver un équilibre entre la liberté d’innovation et le respect des créateurs, alors que les entreprises de l’IA exploitent des données issues de millions d’œuvres sans rétribution équitable. Enfin, le texte envisage un futur où l’IA, en devenant décentralisée et personnalisée, pourrait redonner aux utilisateurs et aux artistes un meilleur contrôle sur la diffusion et la monétisation des contenus culturels.
Table des matières
- 1. Deepseek: vers une décentralisation de l’IA?
2.. Modèles d’IA et individus: le dilemme de la cogénération des données
1. Deepseek: vers une décentralisation de l’IA?
L’arrivée du dernier modèle Deepseek en janvier dernier a créé bien des remous et provoque une remise en question du modèle économique des entreprises de l’IA. Sur le plan financier, Bloomberg évalue que l’événement a provoqué une dévaluation d’environ un trillion $ d’actions d’entreprises américaines liés à ce secteur. Les investisseurs n’avaient vraisemblablement pas anticipé la menace que représente Deepseek pour le modèle d’affaires des grandes entreprises technologiques du pays.
Le marché de l’IA est en effet dominé jusqu’à maintenant par de grandes entreprises étatsuniennes : Microsoft (OpenAI), Google (GEMINI), META (LLAMA) et Anthropic (Claude). La plupart des observateurs du secteur de l’IA estimaient que ces entreprises avaient pris une avance considérable sur leurs éventuels compétiteurs étrangers, d’autant plus que le gouvernement américain s’est assuré que la Chine ne pouvait avoir accès aux puces GPU (Graphic Processing Unit) de Nvidia, considérées comme étant indispensables au développement des modèles d’IA. Les performances de Deepseek sont non seulement surprenantes, mais le peu de moyens qui semblent avoir été utilisés pour y arriver remet en question la domination des grandes entreprises étatsuniennes, perçues jusqu’à maintenant comme étant les seules à disposer des moyens nécessaires au développement de ce secteur économique.
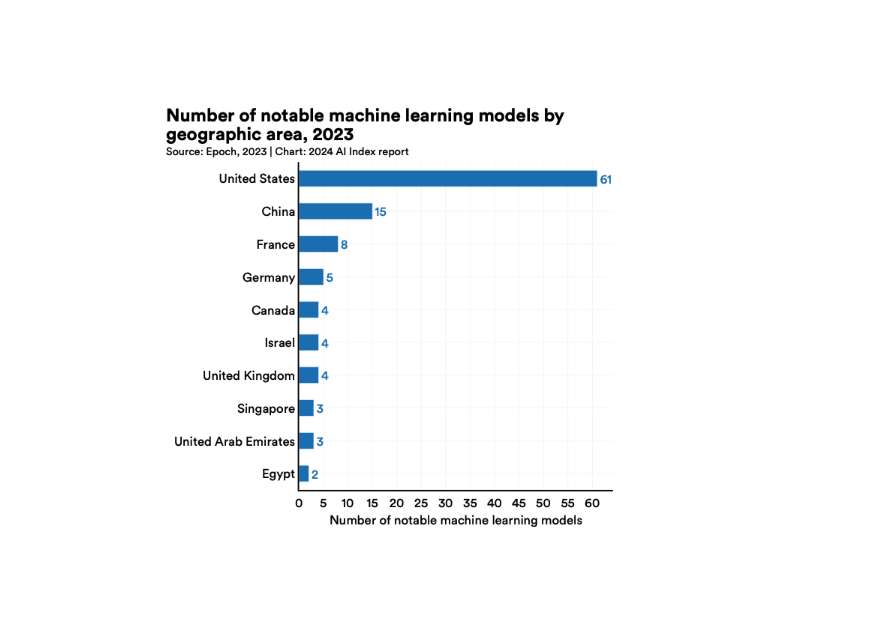
Source : World Economic Forum, Janvier 2025. https://www.weforum.org/stories/2025/02/open-source-ai-innovation-deepseek/
Sur le plan politique, le développement par les Chinois de modèles d’IA très performants à un coût très inférieur à ceux de Microsoft et compagnie pose plus intimement que jamais la question de la latitude laissée par les gouvernements aux technologies chinoises capables de récolter des données sur les utilisateurs occidentaux. Le gouvernement australien a décidé ces derniers jours d’interdire l’utilisation de Deepseek sur tous les appareils gouvernementaux. Il serait étonnant que le gouvernement américain n’en fasse pas de même, la US Navy, la NASA et le Congrès ayant déjà banni son utilisation par leurs employés. Plusieurs États ont pris contact avec Deepseek afin de mieux connaître quelles sont ses politiques de respect de la vie privée et de gestion des données des utilisateurs. Les pressions pour encadrer, voire interdire l’utilisation de Deepseek se manifestent ainsi dans plusieurs États à travers le monde.
La question de l’utilisation par le gouvernement chinois des données récoltées par Deepseek est en effet très sensible pour les gouvernements occidentaux. Le modèle d’IA chinois entre de plein fouet dans la lutte politique, économique et technologique entre les États-Unis et la Chine, d’autant plus que les entrepreneurs étatsuniens étaient jusqu’à récemment convaincus d’avoir quelques années d’avance sur les Chinois dans la recherche sur l’IA. C’est sans doute une importante raison pour laquelle Deepseek a rendu disponible le code de son modèle et proposé une version qui offre la possibilité d’opérer une version “distillée” de son modèle sans avoir à communiquer avec l’infonuagique de l’entreprise. En effet, la version web du modèle recueille les données des utilisateurs et les transmet à l’entreprise. Mais il est également possible d’utiliser une version autonome du modèle, sur des outils informatiques locaux, sans avoir à transférer les données d’utilisation à Deepseek.
Les questions géopolitiques ont leur importance certes, mais cette veille s’intéresse aux impacts des technologies de l’IA sur la culture. Ce qui nous apparaît comme étant le plus intéressant pour le monde de la culture et de la création est l’impact de Deepseek sur les créateurs et sur la nature de leur relation avec le public. Une des principales questions posées à l’industrie de la musique aujourd’hui est à savoir si l’IA va bousculer à la fois nos façons de créer et nos façons de prendre contact comme public avec les œuvres.
Pour les créateurs, il s’agit d’une part de savoir quelle est la partie de leur travail qui sera remplacée par l’IA, mais également comment les outils de création vont se transformer au cours des prochaines années pour donner lieu à de nouvelles manières de créer, voire de nouveaux styles ou genres artistiques. Pour les industries culturelles et les entreprises de l’IA, il est crucial de comprendre comment s’articulera le lien entre le public et les œuvres.
Afin de réfléchir à ces questions, voyons en quoi le modèle de Deepseek a le potentiel de transformer notre relation avec les modèles d’IA. On note deux caractéristiques de Deepseek qui le distingue des principaux modèles développés par les entreprises étatsuniennes. La première est la frugalité du modèle. Deepseek est beaucoup moins exigeant en termes de matériel et d’énergie que les modèles concurrents pour accomplir des tâches similaires. Nous n’entrerons pas dans les détails techniques qui permettent à Deepseek de réussir ainsi, contentons-nous de mentionner que son design permet d’activer ou non une série de sous-modules selon le type de requêtes qui lui sont offertes plutôt que de solliciter l’ensemble du modèle d’IA. Deepseek permet ainsi d’opérer un modèle d’IA à une fraction du coût de ses concurrents.
La seconde est l’ouverture du modèle de Deepseek, qui, sans donner accès aux données qui ont été utilisées pour son entraînement, donne accès à la recette de son modèle. Son code et les explications techniques complètes sont librement disponibles. Ceci permet aux intéressés de partir de cette recette pour l’adapter à leurs besoins, sans qu’il soit nécessaire d’avoir autrement recours aux services de Deepseek. Par exemple, il serait donc possible de créer une IA québécoise à partir du modèle de Deepseek, de l’adapter à nos besoins et de le faire de manière indépendante de l’entreprise chinoise. L’ouverture du modèle permet également de réduire les coûts de développement de Deepseek. Le libre accès au code favorise le développement d’une communauté de développeurs, ce qui encourage l’amélioration du modèle d’IA à faible coût.
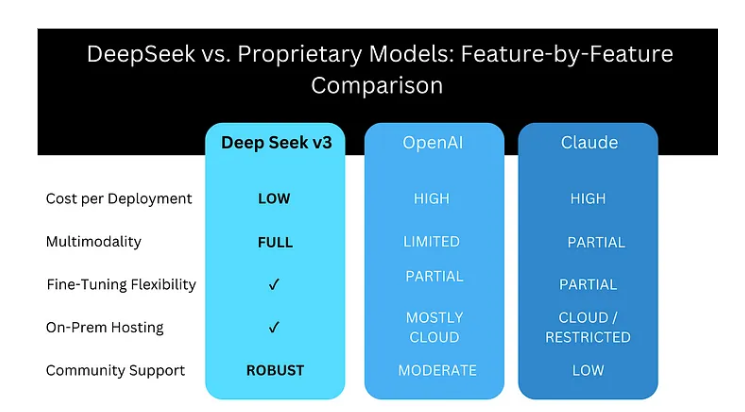
Source : Medium, janvier 2025. https://ai.gopubby.com/the-open-source-ai-revolution-2025-how-deepseek-v3-is-making-100m-ai-systems-available-to-c23bcd853f8c
Ces deux caractéristiques ont à notre avis le potentiel de transformer de manière importante l’écosystème de la culture. Nous sommes tentés de comparer la frugalité et l’adaptabilité de Deepseek à l’apparition de l’ordinateur personnel. Jusqu’à l’apparition du pc, l’ordinateur était une immense machine accessible uniquement aux organisations disposant de moyens conséquents. Les grands modèles d’IA nécessitent aujourd’hui des infrastructures de grande envergure sur le nuage consommant beaucoup d’énergie. Deepseek peut se déployer sur des machines plus modestes sans qu’il soit nécessaire de procéder à l’analyse d’une requête par les infrastructures infonuagiques (c’est ce qu’on appelle en anglais “on-prem hosting”, que l’on retrouve dans le tableau plus haut). Il permet également d’utiliser sa technologie pour l’adapter à des besoins particuliers, sans pour autant être lié à des licences d’exploitation, telles que celles que requiert l’utilisation des modèles de Google ou de META.
Si l’on se projette dans l’avenir, avec les risques que cela comporte, nous pouvons imaginer un monde où les interactions entre le public et les artistes se feront de manière différente de celles que nous connaissons aujourd’hui. Les plateformes numériques comme Netflix ou Spotify dominent les industries culturelles depuis une quinzaine d’années. Leur mode de fonctionnement est très critiqué par les artistes et les producteurs, particulièrement pour ce qui est de la très faible rémunération qui est offerte à la plupart d’entre eux. Le modèle des plateformes numériques est-il menacé par une éventuelle décentralisation de l’IA?
Pour tenter de répondre à cette question, revenons à l’évaluation de ce qu’offre comme services une plateforme telle que Spotify :
- La constitution d’une base de données pour pratiquement toute la musique enregistrée.
- La mise en œuvre d’un moyen de paiement par les utilisateurs pour rémunérer les artistes et les producteurs.
- L’utilisation d’algorithmes pour tenter de proposer à ses utilisateurs de la musique qu’ils pourront apprécier.
- L’organisation d’une interface conviviale qui permet aux utilisateurs d’avoir facilement accès à la musique qu’ils recherchent.
- La promotion de certaines œuvres des artistes et de leurs spectacles à l’aide de la visibilité qu’offre la plateforme.
Nous pouvons d’abord nous poser la question si la gestion des banques de données par les plateformes est la méthode la plus efficace. Les œuvres musicales parviennent généralement aux plateformes par le biais d’un distributeur numérique. Les plateformes doivent conjuguer avec l’arrivée de dizaines, voire de centaines de milliers d’œuvres musicales par jour. Les artistes, producteurs et distributeurs doivent établir des canaux de distribution avec les quelques centaines de plateformes numériques qui offrent des services musicaux. Les coûts de gestion de la base de données doivent être importants pour chacune des plateformes. Rappelons que Spotify dépense annuellement environ 4 milliards $ pour ses frais d’exploitation, alors que l’industrie mondiale de la musique génère au total un peu moins de 30 milliards $. Si l’on additionne les frais d’exploitation des plateformes telles que Apple Music, Deezer et les centaines d’autres qui offrent ce type de services, on voit qu’une part substantielle des revenus totaux de la musique se dirigent vers l’opération des plateformes. Malgré cela, celles-ci ont de la difficulté à générer des profits…
On peut imaginer une structure de fonctionnement de la distribution de la musique où le fichier numérique d’une œuvre musicale n’existerait qu’à un seul endroit. Les sociétés de gestion collective, telles que la SOCAN, l’ASCAP ou la SACEM administrent déjà les droits d’auteur des auteurs, compositeurs et éditeurs. Elles ont un lien direct avec chaque œuvre dont l’un de leurs membres est propriétaire. Elles assurent le lien entre les diffuseurs et leurs membres pour veiller à leur rémunération. Serait-il possible de centraliser les fichiers numériques des œuvres musicales des membres au sein d’une banque de données gérée par leur société de gestion? Techniquement, il ne nous semble pas que la tâche soit extraordinairement complexe, bien qu’elle demande beaucoup de travail, initialement et dans son entretien, ainsi qu’un réseau de diffusion numérique solide, capable de recevoir un grand nombre de requêtes. Il faut également en assurer la sécurité et la redondance, les risques associés à la constitution d’une seule banque de données étant nombreux (cyberattaque, confidentialité, défaillance, performance).
Une telle structure de banque de données offrirait de nombreux avantages. Le premier est que la constitution d’une base de données par société de gestion devrait permettre de réduire considérablement les coûts qui y sont associés. Le coût initial serait sans doute important, mais il pourrait être récupéré par les avantages économiques liés à la maîtrise de sa propriété. En effet, les méthodes de répartition des revenus versés par les utilisateurs des plateformes demeurent sous le contrôle de celles-ci.
Bien malin est celui qui mettra la main sur la formule de répartition des revenus de Spotify. C’est à se demander si quelqu’un comprend seulement ce qui se passe, quels sont les choix qui sont faits devant des arbitrages qui sont compliqués. Par exemple, le coût des abonnements premium à Spotify varie beaucoup d’un État à l’autre, allant de plus de 15 US$ à moins de 1US$ dans certains pays. Quelle est la valeur d’une écoute au Pakistan par rapport à celle d’une écoute en Suisse? Les utilisateurs suisses, qui écoutent de la musique nationale, ne voient-ils pas une partie importante de la valeur de leur abonnement se diriger vers des œuvres qu’ils n’écoutent pas du tout? Il existe une foule de questions sur cette répartition, sans même parler des ententes exclusives de Spotify avec les trois multinationales du disque, de nature privée, qui leur assure sans doute la plus importante part du gâteau. L’équité de la répartition des revenus de la musique est une question centrale à la pérennité des créations culturelles nationales et il ne nous semble pas qu’il soit possible de remédier aux principaux problèmes posés par le cadre actuel.
Un problème est cependant soulevé par la question des moyens utilisés pour mettre en contact économiquement les amateurs de culture du monde entier et les œuvres des artistes. C’est une des forces des plateformes numériques que d’être capables de donner accès à la culture presque partout dans le monde tout en étant capables de monnayer cet accès. Une décentralisation vers les sociétés de gestions collectives pourrait rendre cet accès plus complexe. Comment faire en sorte qu’un Japonais qui écoute de la musique québécoise verse un montant à la SOCAN pour cette écoute, sans que le système de rémunération ne devienne trop complexe? La solution à ce problème pourrait passer par l’établissement d’une valeur mondiale de l’écoute d’une œuvre et par une gestion locale des revenus générés par les amateurs de musique. Ainsi, les sociétés de gestion collective pourraient veiller au paiement des écoutes internationales de leurs citoyens. Nous pourrions alors constater avec précision quelle est la nature des transferts économiques en matière de culture entre les différents États dans le monde.
En disposant du contrôle sur la base de données, les sociétés de gestion assureraient le suivi des écoutes et pourraient établir leur valeur. Ce mode de fonctionnement réduirait les intermédiaires en jouant le rôle des distributeurs numériques. Elles amélioreraient également leur rapport de force pour négocier des droits conséquents pour l’accès aux œuvres de leurs membres. À notre avis, les artistes et les producteurs tireraient avantage d’une telle organisation, autant sur le plan des dépenses de fonctionnement que sur celui des revenus générés.
Cependant, la mise en place d’une telle structure n’aurait vraisemblablement pas de sens s’il n’était pas possible de veiller par un moyen alternatif à la satisfaction des autres fonctions qu’assurent aujourd’hui les plateformes numériques. Afin que les économies soient suffisamment importantes pour justifier les investissements nécessaires aux transformations que nous évoquons, il nous apparaît nécessaire que les frais d’exploitation des plateformes soient considérablement réduits, voire nuls. C’est ici que la décentralisation de l’IA peut intervenir.
L’IA décentralisée pourrait jouer à la fois les rôles que jouent les algorithmes et les interfaces des plateformes numériques. Entraînée sur nos habitudes d’écoute, sur nos préférences et capables d’identifier les nouveautés susceptibles de nous intéresser, l’IA personnelle que nous allons sans doute placer dans nos outils de communication pourra s’avérer plus efficace qu’un algorithme centralisé tel que celui qu’utilise Spotify. De plus, nous serons à même de configurer cet algorithme à notre manière, reprenant ainsi une part du contrôle sur le choix des œuvres qui nous sont offertes. La possibilité d’intervenir directement auprès de l’algorithme pour en améliorer l’efficacité échappe encore aujourd’hui aux usagers des plateformes numériques qui demeurent sujets de leur technologie. Cette prise de contrôle des algorithmes par l’usager va dans le sens d’une IA centrée sur l’humain, respectant les principes d’IA responsable que nous souhaitons voir mis de l’avant.
L’interface pour écouter de la musique ou un film pourrait être intégrée à celle que nous utiliserons pour notre vie courante, de la gestion d’horaire à celle des communications internet. On peut déjà entrevoir le jour où l’IA fera partie de notre organisation de vie quotidienne. Cette interface pourrait entrer directement en contact avec les œuvres basées dans les sociétés de gestion collective et administrer différentes listes d’écoute personnelles et celles proposées par d’autres personnes ou organisations. Une interface décentralisée nous permettrait également d’ouvrir les champs du possible quant à la prescription de la musique par plusieurs sources différentes qui viendraient appuyer la découverte musicale, plutôt que de demeurer cantonné à une seule plateforme numérique.
La mise en place d’une telle structure présenterait de nombreux avantages. Le contrôle sur la distribution reviendrait entre les mains des créateurs et de leurs représentants. Tel que démontré dans les précédentes veillées, nombreux sont-ils aujourd’hui à se trouver otages des plateformes numériques où ils doivent rendre disponibles leurs œuvres, simplement pour exister socialement, sans pour autant recevoir une juste rémunération. Le pouvoir des multinationales du disque, qui contrôlent aujourd’hui le mode de fonctionnement des plateformes numériques, se trouverait réduit par une décentralisation des algorithmes et des choix éditoriaux, qui se font souvent à l’avantage des premières. Les industries culturelles locales seraient capables de mettre en œuvre des stratégies de promotion en collaboration avec les sociétés de gestion collective, les radios locales et différents lieux de curation de la culture qui pourraient émerger. De plus, les données de consommation sur la culture locale seraient détenues par des organisations locales, qui pourraient les mettre en valeur.
Peut-être rêvons-nous un peu ici. Mais si le rêve existe, c’est parce que la situation dans laquelle nous vivons rend la création locale très difficile. Et ce n’est pas parce que nos artistes sont moins bons qu’ailleurs que leur situation économique s’est détériorée, mais plutôt par la nature même de la formidable centralisation des industries culturelles mondiales que les plateformes numériques ont opérée en quelques années. Les cultures locales ne disparaissent pas d’un coup, mais elle s’étiole plutôt dans le temps à force de rencontrer des vents contraires.
Pour assurer l’avenir de la diversité des expressions culturelles mondiales, il nous apparaît nécessaire d’imaginer comment nous pourrions utiliser les nouvelles technologies pour y arriver. Au cours des vingt-cinq dernières années, ces technologies ont été capturées par des intérêts privés, largement étatsuniens, qui ont permis d’améliorer considérablement les communications et les échanges à travers le monde. Mais cette capture a également eu des effets délétères dont il faut prendre acte et voir comment il est possible de les mitiger, voire de les supprimer. La décentralisation des industries culturelles au profit des individus et des organisations locales nous apparaît comme étant la voie à suivre et l’IA peut nous donner l’opportunité d’y arriver.
2. Modèles d’IA et individus: le dilemme de la cogénération des données
Les grands modèles d’IA sont entraînés à partir de milliards de données générées d’une multitude de manières. Ces données sont au cœur du modèle d’affaires des entreprises parmi les plus grandes au monde. Des ensembles de données fiables, riches et complètes sont essentiels aux modèles d’IA. L’industrie de la donnée est l’une de celles qui ont crû très rapidement au cours des dix dernières années. L’intérêt économique de cette industrie est manifeste et ses particularités posent aux États et au public de nouvelles questions quant à son encadrement.
Les États ont été lents à réagir aux défis posés par le développement du marché des données massives depuis qu’il s’est adapté à internet au cours des années 1990 pour arriver à développer depuis le début des années 2000 les principaux outils fondateurs de l’utilisation massive des données générées par les utilisateurs d’internet.
Il ne nous semble pas étonnant que le leadership en matière de régulation soit assumé par l’Union européenne. Premier marché mondial, l’Union européenne joue depuis plusieurs années déjà en quelque sorte le rôle de régulateur des entreprises d’internet. Le fait que la plupart des multinationales dont les activités reposent sur la mise en valeur des données massives soient basées aux États-Unis n’est sans doute pas étranger à ce rôle qu’elle s’est octroyé.
L’UE a adopté en 2016 le Règlement général sur la protection des données (RGPD). Celui-ci poursuivait l’objectif d’harmoniser les lois nationales de protection de données au sein de l’UE et de renforcer la protection des citoyens quant à la protection de leurs données personnelles. Nous n’entrerons pas dans les détails du RGPD, notre intérêt pour celui-ci étant essentiellement lié à la démonstration du rôle de leader de la régulation d’internet que joue l’Union européenne.
Nous observons que les règles adoptées par l’Union européenne ont la capacité de s’imposer sur la scène mondiale. La puissance de l’UE et l’importance de son marché font en sorte que les règles qu’elle impose sur son territoire provoquent des ajustements aux pratiques sur internet qui peuvent avoir une portée mondiale. Par exemple, les règles que l’UE a mises en place pour la formulation du consentement au partage de données personnelles requis des sites internet sont maintenant largement utilisées par ces derniers dans les échanges qu’elles entretiennent avec tous leurs utilisateurs. Il s’agit d’un mécanisme de transfert mondial des règles et des normes sur internet qui nous interpelle et sur lequel nous reviendrons dans le chapitre sur la régulation.
Dans le cas de la régulation de l’IA, la position de l’UE est moins nette. Des membres tels que la France adopte une position moins tranchée sur la question de l’utilisation des données privées utilisées pour l’entraînement des modèles d’IA. Le fait que la française Mistral AI soit un leader mondial dans le domaine n’est sûrement pas étranger à la position du gouvernement français. Plusieurs scientifiques reconnus dans le secteur de l’IA sont d’ailleurs français et ont participé au développement de modèles américains. Dans la patrie du droit d’auteur, il n’en demeure pas moins que les questions liées à la protection de la propriété intellectuelle ne sont pas prises à la légère. La récente loi sur l’IA de l’Union européenne précise en effet que les entreprises qui développent des modèles d’IA doivent assurer la transparence de leur fonctionnement et le respect de la propriété intellectuelle dans leur entraînement.
Contrairement à la plupart des ressources ou services, la propriété des données n’est pas toujours clairement établie et, lorsqu’elle l’est, les méthodes pour les utiliser sont rarement bien encadrées par la loi ou la réglementation. Qui peut avoir accès aux données et pour quelle raison? Qui décide quelles données sont utilisées pour un projet ou une entreprise? Quelles données peuvent être partagées d’une entreprise à l’autre? Peut-on clairement identifier quelles sont les données qui ont été utilisées pour l’entraînement d’un modèle d’IA? Qui doit bénéficier de la valeur créée par les données? Ces questions sont souvent évitées par les entrepreneurs de l’IA qui manifestent une certaine impatience face à d’éventuelles régulations qui brideraient l’évolution des outils technologiques qu’ils souhaitent développer.
Les données, du moins celles qui nous intéressent ici, sont généralement le résultat d’une action humaine. Nous pouvons arguer que nous sommes à la fois responsables et propriétaires de nos actions. Nous avons déjà évoqué dans une veille précédente la question de l’utilisation de millions de chansons du répertoire mondial pour l’entraînement des modèles d’IA capables de proposer de nouvelles chansons à partir des données récoltées.
Le débat sur ce qui constitue une « utilisation équitable » des données et du contenu collectés sur Internet est très vif. La croissance continue du nombre et de la diversité des poursuites judiciaires autour de l’IA générative, ainsi que les efforts accrus des décideurs politiques pour suivre le rythme de la réglementation, indiquent l’ampleur du problème à résoudre. Les États doivent tenter de trouver un équilibre en matière de cogénération des données. D’une part, les ayants droit se trouvent bien justifiés de réclamer le respect de leur création lorsqu’elles sont utilisées par des entreprises pour créer des modèles d’IA capables de les imiter. La valeur potentielle captée par les entreprises de l’IA provient en grande partie du travail de millions de créateurs qui n’y trouve non seulement aucun intérêt, mais parfois même un nouveau concurrent qui peut rapidement éclipser le créateur original!
D’autre part, les modèles d’IA ont le potentiel de nous aider à trouver des solutions à de nombreux problèmes importants pour l’humanité. Il faut donc que les États agissent avec circonspection dans l’encadrement des entreprises de l’IA afin de ne pas nuire à l’innovation qui pourrait se révéler cruciale pour relever certains défis.
Il apparaît donc nécessaire d’explorer des manières originales d’encadrer les activités des entreprises de l’IA afin que les droits des créateurs soient respectés, sans pour autant limiter les capacités d’innovation de ces entreprises. Il s’agit d’un défi sur lequel nous reviendrons dans la prochaine veille, qui traitera de la régulation de l’IA.
Cet article est le résultat d’une collaboration entre LATICCE-UQAM, CEIMIA et Mitacs.
Les opinions exprimées et les arguments avancés dans cette veille demeurent sous l’entière responsabilité du rédacteur.
- Direction scientifique : Michèle Rioux, directrice du LATICCE
- Rédaction : Guy-Philippe Wells, directeur scientifique du LATICCE
- Coordination : Janick Houde et Arnaud Quenneville-Langis du CEIMIA
- Révision : Mathieu Marcotte du CEIMIA
- Centre d’expertise international de Montréal en intelligence artificielle (CEIMIA)
- 7260 Rue Saint-Urbain, Montréal, QC H2R 2Y6, suite, 602, CANADA. Site web: www.ceimia.org
- Centre d’études sur l’intégration et la mondialisation (CEIM)
- UQAM, 400, rue Sainte-Catherine Est, Pavillon Hubert-Aquin, bureau A-1560, Montréal (Québec) H2L 2C5
- CANADA. Téléphone : 514 987-3000, poste 3910 / Courriel: ceim@uqam.ca / Site web: www.ceim.uqam.ca